(a) Better: flexible method incorporates the data better when the sample size is large enough.
(b) Worse: The data set leads to the ‘Curse of Dimensionality’, flexible model will tend to be more overfitting, meaning it will try to follow the error (noise) too closely.
(c) Better: Flexible methods perform better on non-linear datasets as they have more degrees of freedom to approximate a non-linear.
(d) Worse: A flexible model would likely overfit, due to more closely fitting the noise in the error terms than an inflexible method. In other words, the data points will be far from f (ideal function to describe the data) if the variance of the error terms is very high. This hints that that f is linear and so a simpler model would be better to be able to estimate f.
Question 2
(a) Regression Problem: Since it is a quantitative problem Inference: We are interested in the factors which affect CEO salary n = 500 p = 3 (Profit, number of employees, industry)
(b) Classification Problem: Since it is binary (success or failure) Prediction: We are interested in the success or failure of the product n = 20 p = 13 (Price charged, marketing budget, competition price + 10 other)
(c) Regression Problem Prediction: We are interested in the % change in the USD/Euro exchange rate n = 52 p = 3 (% change in the US market, % change in the British market, % change in the German market)
Question 3
(a)
(b) Squared Bias: Decreases with more flexibility (generally more flexible methods results in less bias)
Variance: Increases with more flexibility
Training Error: Continues to reduce as flexibility grows, meaning the model is too close to the training data.
Test Error: Decreases initially, and reaches the optimal point where it gets flat, then it starts to increase again, meaning an overfitted data
Bayes (irreducible) Error: Flat/Fixed, since it can’t be reduced any more
Question 4
(a) Three real-life applications in which classification might be useful
1. Email Spam Detection
Response: Spam(1) or Not Spam(0)
Predictors: some special words, special links, other
Goal: Prediction — we care more about classifying new emails correctly than about interpreting which word exactly causes spam.
2. Loan Default Risk
Respone: Default(1) or Won’t Default(0)
Predictors: income, credit score, education, etc
Goal: Prediction/Inference — banks want to predict default risk, but also understand which factors matter most
3. Stock Price
Response: Stock increases(1) or Stock goes down(0)
Predictors: Financial Statements, Ratio Analysis, Competitors price, etc
Goal: Prediction — we are interested in making the future movements of the stock price.
(b) Three real-life applications in which regression might be useful:
1. House Price Estimation
Response: House price (in $).
Predictors: square footage, number of bedrooms, location, age of house.
Goal: Prediction — estimate the price of houses not yet sold.
2. Salary Determination
Response: Employee salary (in $).
Predictors: years of experience, education level, industry, job role.
Goal: Inference — HR might want to know which factors (experience vs. education) most strongly drive salaries.
3. Insurance Premium Calculation
Response: Annual premium amount.
Predictors: age, medical history, smoking status, BMI.
Goal: Both — insurers need prediction for pricing policies, but also inference to understand key risk drivers.
(c) Three real-life applications in which cluster analysis might be useful:
Goal: Find natural clusters of users (e.g., sports fans, political groups, hobby communities).
Question 5
Advantages of a More Flexible Approach
Better fit to complex patterns: Can capture nonlinear relationships and intricate interactions between variables.
Lower bias: Since fewer assumptions are made about the functional form, the model can adapt closely to the data.
High predictive power: Often yields better test accuracy if enough data is available.
Disadvantages of a More Flexible Approach
Risk of overfitting: May capture noise in the training data instead of the true signal.
Higher variance: Predictions can change drastically with new data.
Interpretability: Flexible models are often “black boxes” (e.g., random forests, neural nets).
Computational cost: More data and resources needed for training.
Advantages of a Less Flexible Approach
Simplicity: Easy to implement, interpret, and explain to stakeholders.
Low variance: Less sensitive to small changes in the dataset.
Efficient: Works well with smaller datasets, requires less computation.
Inference: Easier to test hypotheses and understand relationships between predictors and response.
Disadvantages of a Less Flexible Approach
High bias: May oversimplify reality by assuming linearity or ignoring interactions.
Poor fit for complex relationships: If the true relationship is nonlinear, performance suffers.
When to prefer More Flexible Approaches
When prediction accuracy is the main goal.
When the relationship between predictors and response is complex and nonlinear.
When you have large amounts of data to reduce variance and prevent overfitting.
When to prefer Less Flexible Approaches
When the primary goal is inference/interpretability (understanding which predictors matter).
When you have limited data, flexible models overfit easily with small datasets.
When stakeholders (like regulators, executives) need transparent models.
Question 6
Parametric: Assume a functional form (e.g., linear regression), then estimate a few parameters.
Advantage: Works with small data, simple, interpretable, fast.
Disadvantage: Risk of bias if model form is wrong, limited flexibility.
Non-Parametric: No strict form, model is shaped by the data (e.g., KNN, trees).
Advantage: Very flexible, can capture complex patterns.
Disadvantage: Needs lots of data, higher variance, less interpretable, slower.
Question 7
(a) Computing the Euclidean distance between each observation and the test point, X1 = X2 = X3 = 0
(data.set <-data.frame("X1"=c(0,2,0,0,-1,1),"X2"=c(3,0,1,1,0,1),"X3"=c(0,0,3,2,1,1),"Y"=c("Red","Red","Red","Green","Green","Red") )) # A given data set
X1 X2 X3 Y
1 0 3 0 Red
2 2 0 0 Red
3 0 1 3 Red
4 0 1 2 Green
5 -1 0 1 Green
6 1 1 1 Red
euclidian.distance <-function(X, pred.data){# 'X' here represents a vector of points distance =sqrt((X[1]-pred.data[1])^2+ (X[2]-pred.data[2])^2+ (X[3]-pred.data[3])^2) return(distance) } # A function to compute euclidian distance
X <- data.set[,-4] # Taking only the given X co-ordinatesPrediction.coordinates <-c(0,0,0) # Prediction co-ordinatesdistance <-numeric()for(i in1:nrow(X)){ distance[i] =as.matrix(euclidian.distance(X[i,], Prediction.coordinates))}distance <-as.matrix(distance)cat("\n","dist(New,Obs1) =",distance[1,1],"\n","dist(New,Obs2) =",distance[2,1],"\n","dist(New,Obs3) =",distance[3,1],"\n","dist(New,Obs4) =",distance[4,1],"\n","dist(New,Obs5) =",distance[5,1],"\n","dist(New,Obs6) =",distance[6,1],"\n" )
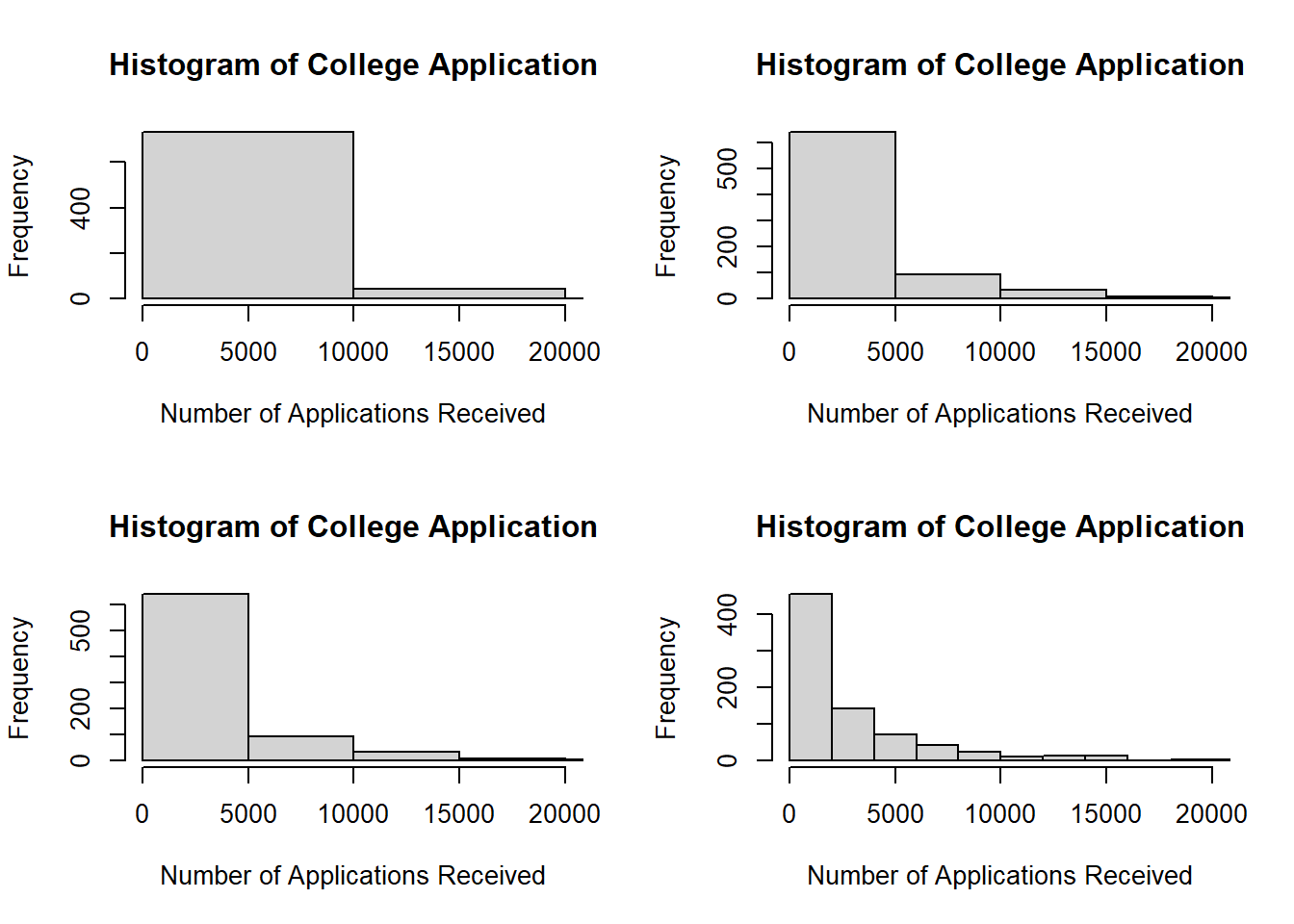
# v.par(mfrow =c(2,2))# FOR COLLEGE APPLICATIONS RECEIVEDfor(n inc(5,10,15,20)){hist(college$Apps, xlab ="Number of Applications Received",main ="Histogram of College Application",breaks = n,xlim =c(0,20000))}
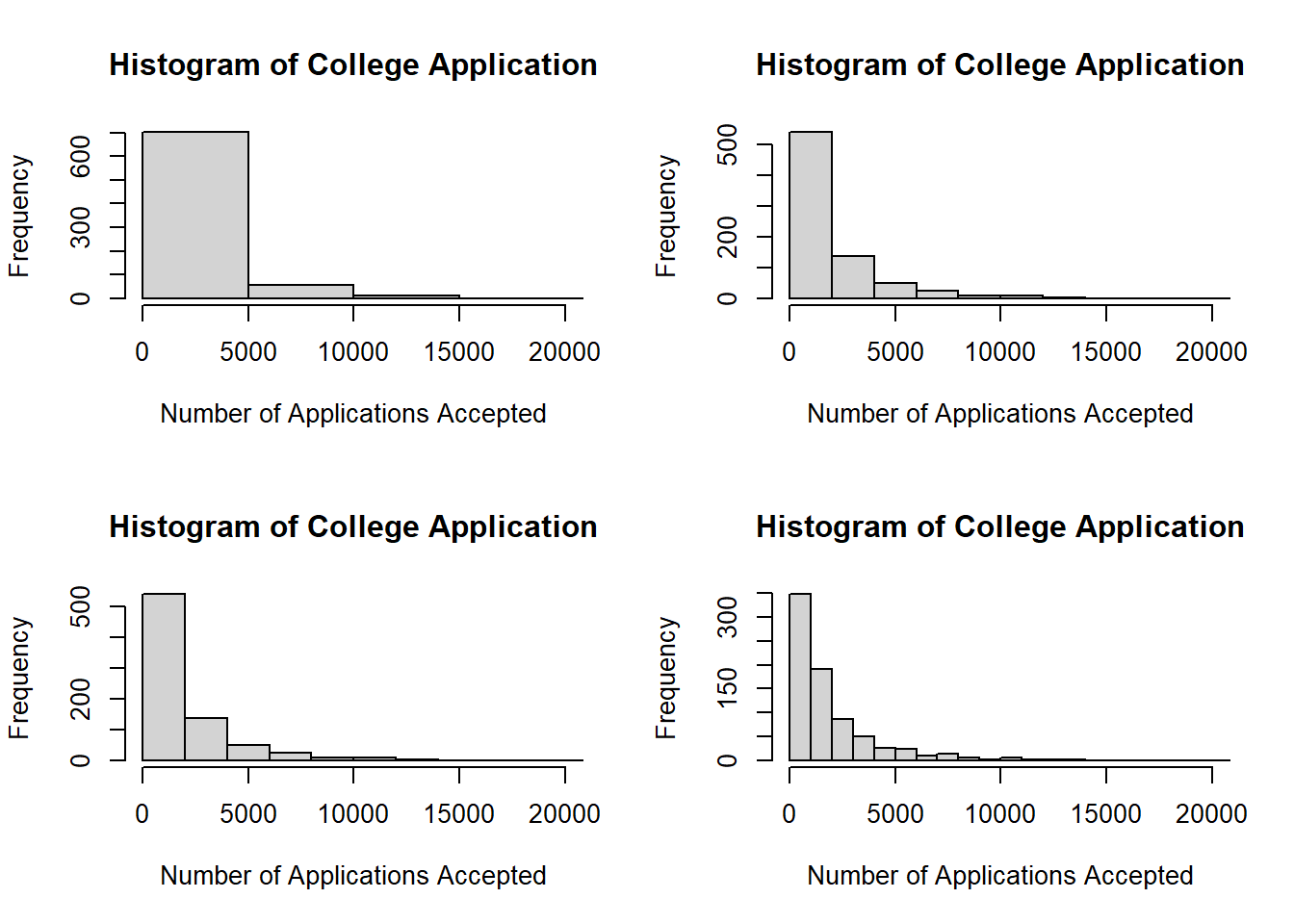
par(mfrow =c(2,2))# FOR COLLEGE APPLICATIONS ACCEPTEDfor(n inc(5,10,15,20)){hist(college$Accept, xlab ="Number of Applications Accepted",main ="Histogram of College Application",breaks = n,xlim =c(0,20000))}
par(mfrow =c(1,1))
# vi.# Making a linear model with all variablesModel1 <-lm(Accept~.,data=College)summary(Model1)
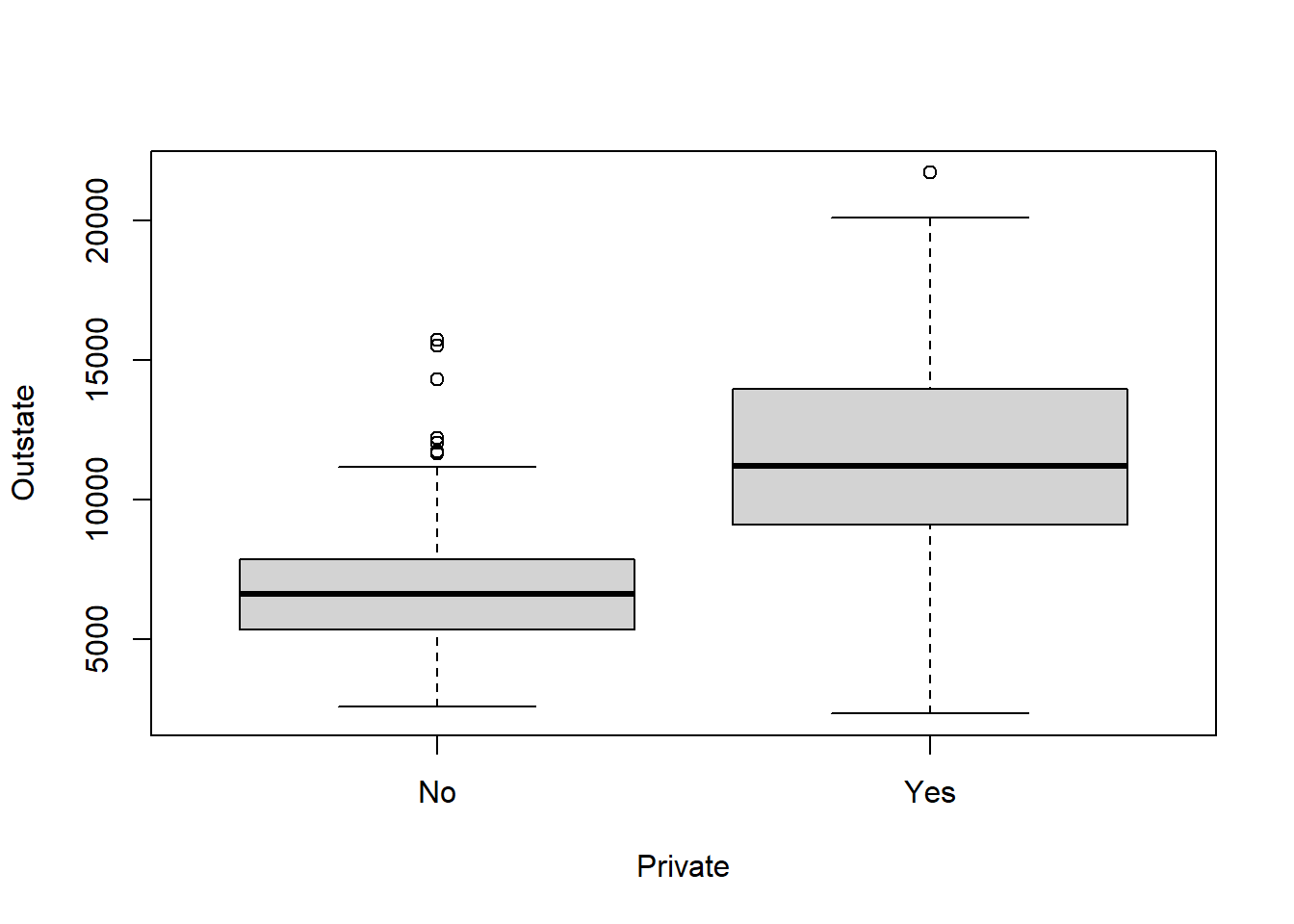
# Using this model to determine all the significant parameters which comes out # to be:# -> Private# -> Apps# -> Enroll# -> Top10perc# -> Top25perc# -> P.Undergrad# -> Outstate# -> perc.alumni# -> Expend# Making another model with these parameters only:Model2 <-lm(Accept ~ Private + Apps + Enroll + Top10perc + Top25perc + P.Undergrad + Outstate + perc.alumni + Expend,data=College)summary(Model2)
Overall Model 2 is better, but if I wanted to use as less co-variates as possible in order to explain most of the response variable, I can use Model 4 as well.
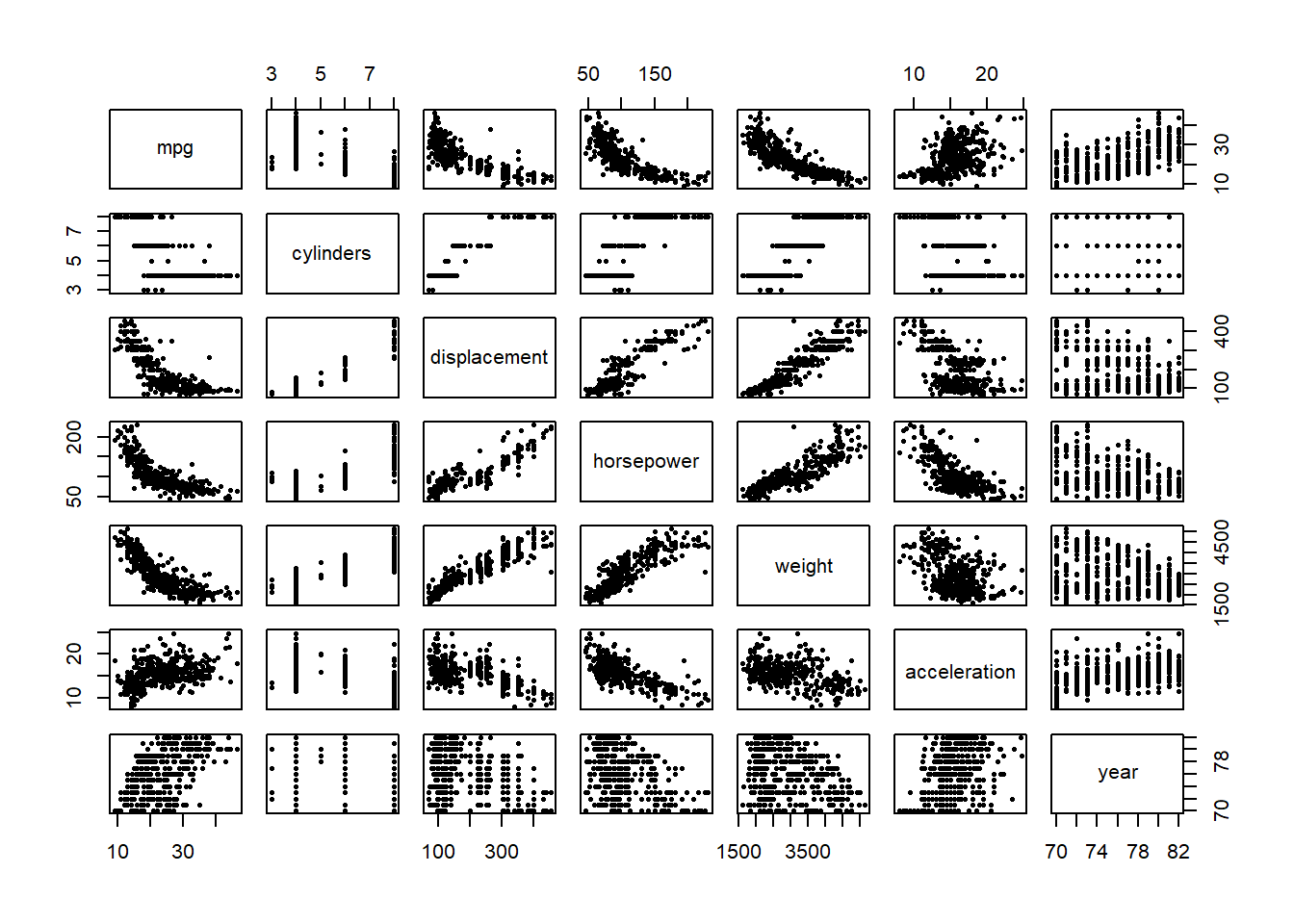
The covariates with high positive correlation are (more than 0.7): cylinders vs displacement cylinders vs horsepower cylinders vs weight displacement vs horsepower displacement vs weight horsepower vs weight
The covariates with high negative correlation are (less than -0.7): mpg vs cylinders mpg vs displacement mpg vs horsepower mpg vs weight
(f)
Yes, all the other variables except acceleration (maybe even year) are highly correlated and can be used to predict mpg.
medv parameter has good positive correlation with rm and high negative correlation with lstat
indus parameter has high positive correlation with nox and tax, and high negative correlation with dis
and many more…
(c)
crm (per capita crime rate by town) has the highest correlation with rad (index of accesssibility to radial highways) which is positive.
(d)
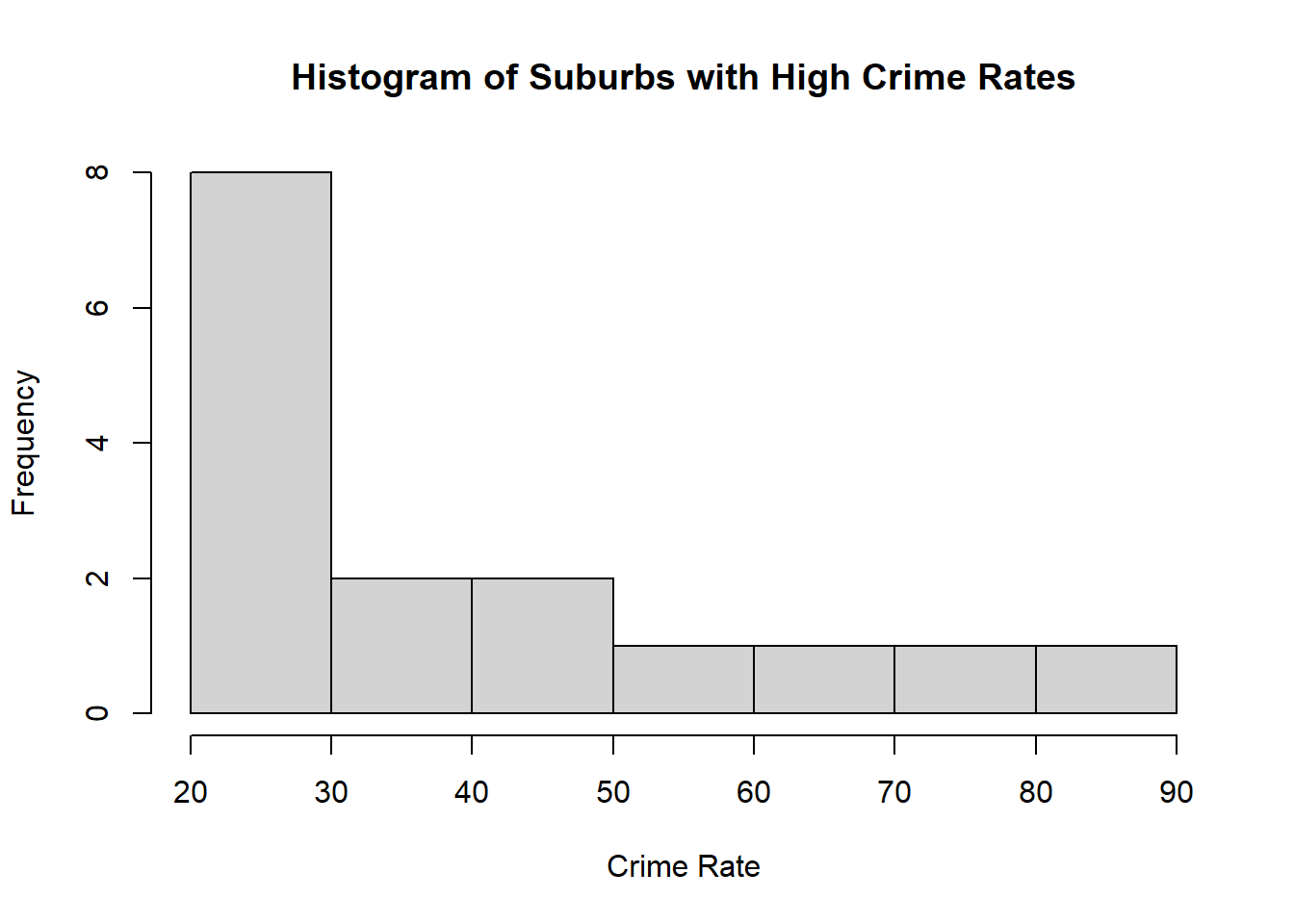
# High Crime RatesHigh.Crime.Rate <- Boston$crim[Boston$crim >mean(Boston$crim) +2*sd(Boston$crim)]cat("There are",length(High.Crime.Rate),"suburbs which have high crime rate")
There are 16 suburbs which have high crime rate
hist(High.Crime.Rate,xlab ="Crime Rate",main ="Histogram of Suburbs with High Crime Rates")
range(High.Crime.Rate)
[1] 22.0511 88.9762
# High Tax RatesHigh.Tax.Rate <- Boston$tax[Boston$tax >mean(Boston$tax) +2*sd(Boston$tax)]cat("There are",length(High.Tax.Rate), "suburbs which have high tax rate")
There are 0 suburbs which have high tax rate
# High Pupil-teacher ratiosHigh.Pupil.teacher.ratios <- Boston$ptratio[Boston$ptratio >mean(Boston$ptratio) +2*sd(Boston$ptratio)]cat("There are",length(High.Pupil.teacher.ratios),"suburbs which have high Pupil-teacher ratio")
There are 0 suburbs which have high Pupil-teacher ratio
(e)
cat(“There are”,sum(Boston$chas),“suburbs that bound the Charles river.”)
(f)
cat(“Median pupil-teacher ratio in town is”,median(Boston$ptratio))
crim zn indus chas
Min. : 0.00632 Min. : 0.00 Min. : 0.46 Min. :0.00000
1st Qu.: 0.08205 1st Qu.: 0.00 1st Qu.: 5.19 1st Qu.:0.00000
Median : 0.25651 Median : 0.00 Median : 9.69 Median :0.00000
Mean : 3.61352 Mean : 11.36 Mean :11.14 Mean :0.06917
3rd Qu.: 3.67708 3rd Qu.: 12.50 3rd Qu.:18.10 3rd Qu.:0.00000
Max. :88.97620 Max. :100.00 Max. :27.74 Max. :1.00000
nox rm age dis
Min. :0.3850 Min. :3.561 Min. : 2.90 Min. : 1.130
1st Qu.:0.4490 1st Qu.:5.886 1st Qu.: 45.02 1st Qu.: 2.100
Median :0.5380 Median :6.208 Median : 77.50 Median : 3.207
Mean :0.5547 Mean :6.285 Mean : 68.57 Mean : 3.795
3rd Qu.:0.6240 3rd Qu.:6.623 3rd Qu.: 94.08 3rd Qu.: 5.188
Max. :0.8710 Max. :8.780 Max. :100.00 Max. :12.127
rad tax ptratio lstat
Min. : 1.000 Min. :187.0 Min. :12.60 Min. : 1.73
1st Qu.: 4.000 1st Qu.:279.0 1st Qu.:17.40 1st Qu.: 6.95
Median : 5.000 Median :330.0 Median :19.05 Median :11.36
Mean : 9.549 Mean :408.2 Mean :18.46 Mean :12.65
3rd Qu.:24.000 3rd Qu.:666.0 3rd Qu.:20.20 3rd Qu.:16.95
Max. :24.000 Max. :711.0 Max. :22.00 Max. :37.97
medv
Min. : 5.00
1st Qu.:17.02
Median :21.20
Mean :22.53
3rd Qu.:25.00
Max. :50.00
summary(High.dwelling.Boston)
crim zn indus chas
Min. :0.02009 Min. : 0.00 Min. : 2.680 Min. :0.0000
1st Qu.:0.33147 1st Qu.: 0.00 1st Qu.: 3.970 1st Qu.:0.0000
Median :0.52014 Median : 0.00 Median : 6.200 Median :0.0000
Mean :0.71880 Mean :13.62 Mean : 7.078 Mean :0.1538
3rd Qu.:0.57834 3rd Qu.:20.00 3rd Qu.: 6.200 3rd Qu.:0.0000
Max. :3.47428 Max. :95.00 Max. :19.580 Max. :1.0000
nox rm age dis
Min. :0.4161 Min. :8.034 Min. : 8.40 Min. :1.801
1st Qu.:0.5040 1st Qu.:8.247 1st Qu.:70.40 1st Qu.:2.288
Median :0.5070 Median :8.297 Median :78.30 Median :2.894
Mean :0.5392 Mean :8.349 Mean :71.54 Mean :3.430
3rd Qu.:0.6050 3rd Qu.:8.398 3rd Qu.:86.50 3rd Qu.:3.652
Max. :0.7180 Max. :8.780 Max. :93.90 Max. :8.907
rad tax ptratio lstat medv
Min. : 2.000 Min. :224.0 Min. :13.00 Min. :2.47 Min. :21.9
1st Qu.: 5.000 1st Qu.:264.0 1st Qu.:14.70 1st Qu.:3.32 1st Qu.:41.7
Median : 7.000 Median :307.0 Median :17.40 Median :4.14 Median :48.3
Mean : 7.462 Mean :325.1 Mean :16.36 Mean :4.31 Mean :44.2
3rd Qu.: 8.000 3rd Qu.:307.0 3rd Qu.:17.40 3rd Qu.:5.12 3rd Qu.:50.0
Max. :24.000 Max. :666.0 Max. :20.20 Max. :7.44 Max. :50.0
More average number of room per dwelling results in a lower crime rate